How I Rebuilt CSV Imports to Handle 10,000 Messy Rows Without Breaking
Imports break on real data. Here's how I rebuilt Relaticle's import wizard with staged SQLite storage, smart matching, async validation, and row-level failure handling.
Imports look simple until they aren't. The moment real users bring messy CSVs — ambiguous dates, duplicate rows, partial updates — into a live CRM, a basic importer starts failing in subtle ways.
For Relaticle V3, I rebuilt imports as a dedicated module with a strict workflow, staged processing, and explicit failure handling. This post breaks down the architecture and the tradeoffs behind it.
30-second walkthrough: upload a CSV, map columns, review corrections, and import — without touching production data.
Why I Rebuilt Imports for V3
The old pattern most teams start with is straightforward:
- Parse CSV
- Validate in memory
- Insert/update directly
That works for small clean files. It falls apart the moment someone uploads a CSV where "Acme Corp" appears three different ways, dates mix MM/DD and DD/MM, and half the rows should update existing records instead of creating duplicates.
What you actually need:
- Matching against existing records without false positives
- Safe handling of relationships (company, contact, assignee links)
- Value-level corrections before anything hits the database
- Resumable state and reliable progress tracking
- Clear failure reporting users can act on
For V3, I wanted imports to behave like a proper workflow, not a one-shot script.
Product Flow: 4 Steps, One State Machine
The new Import Wizard is built around four explicit steps:
- Upload CSV
- Map Columns
- Review Values
- Preview and Import
Each step maps to an import status (uploading, mapping, reviewing, previewing, then importing/completed/failed) so the UI and backend stay in sync.
This looks like a UI detail, but it is a reliability decision. You can restore context, prevent invalid transitions, and reason about failures cleanly.
The Key Decision: Stage Data Outside Primary Tables
The most important V3 decision was introducing a per-import staging store.
Instead of writing directly to CRM tables during upload/review, each import gets its own SQLite-backed store (storage/app/imports/<import-id>/data.sqlite). Rows are staged with metadata like:
raw_datavalidationcorrectionsskippedmatch_actionmatched_idrelationshipsprocessed
This separation buys you three things:
- Users review and correct data before anything touches production.
- Matching and validation run repeatedly without data drift.
- Cleanup is trivial: delete the import store directory.
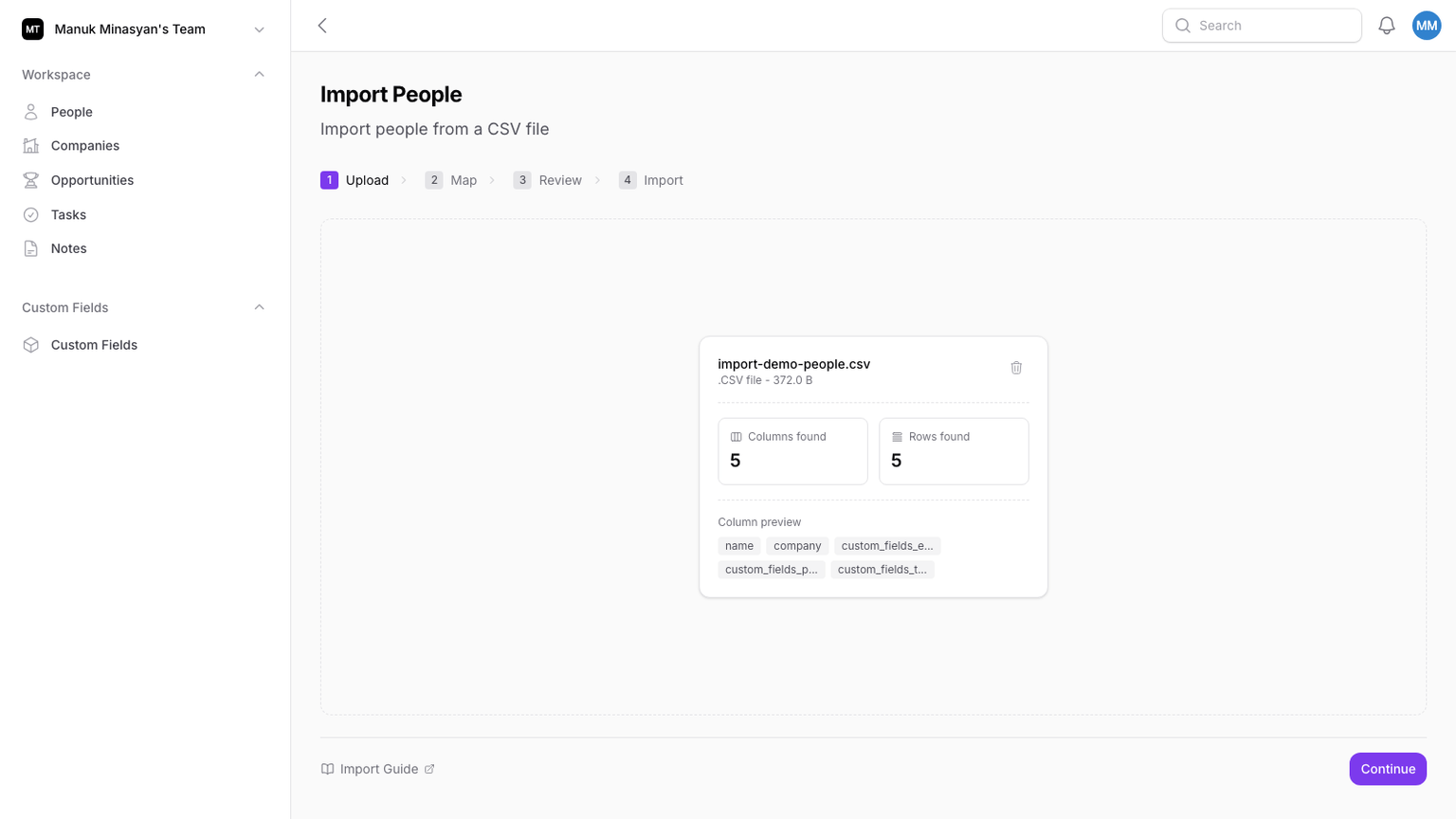
What Happens When Someone Uploads 10,000 Rows?
Upload enforces hard limits:
- Max file size: 10MB
- Max rows: 10,000
- Chunk insert size: 500 rows
- Header sanitization and duplicate-header detection
Rows are streamed from CSV and inserted into the staging store in chunks, not loaded into one huge in-memory structure.
Practical effect: uploads stay stable and fast even with large files, and failure modes are explicit (empty file, duplicate headers, too many rows, bad format).
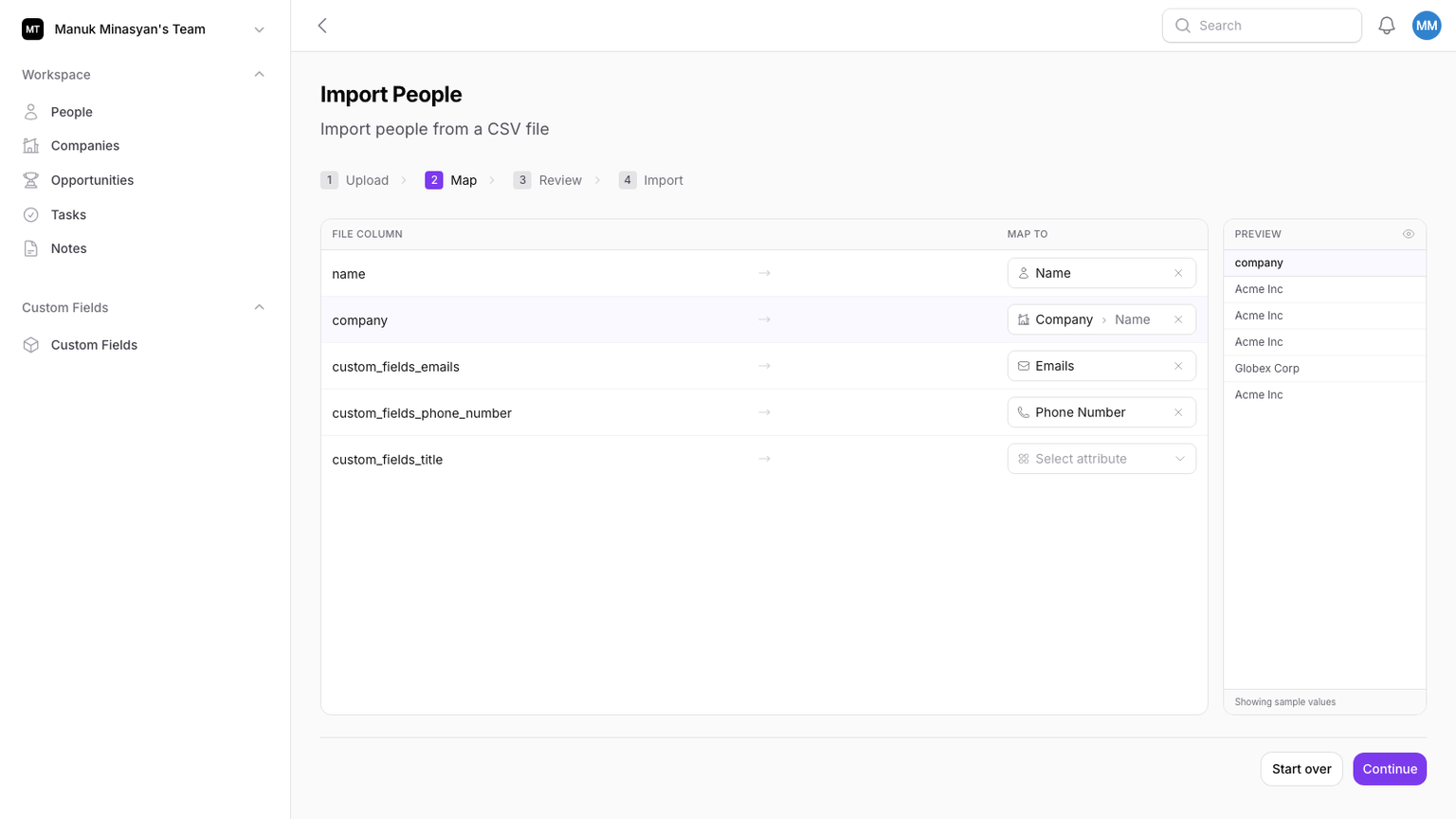
Smart Mapping: Automation With an Escape Hatch
Mapping combines three layers:
- Header-based guesses (aliases like
company_name,contact_email, etc.) - Entity-link mapping for relationships (company, contact, assignee, polymorphic links)
- Data-type inference for unmapped columns
The type inference is driven by the custom-field system, not a static hardcoded map. That keeps behavior aligned with actual field configuration per team/entity.
If users skip mapping any matchable field (like ID, email, or domain), the wizard warns them they may create duplicates. It does not silently continue as if everything is fine.
Review: Where Most Importers Stop, V3 Keeps Going
On entering the Review step:
- A validation job is dispatched per mapped column
- A separate match-resolution job is dispatched
This means users can start interacting with results while backend jobs complete, instead of waiting on one synchronous validation wall.
Users can:
- Fix invalid values once and apply those corrections to all matching raw values
- Skip problematic values
- Adjust date/number formats when ambiguity exists
Everything is persisted in staged JSON fields, so each correction is deterministic and replayable.
Matching Model: Create, Update, or Skip
The resolver marks each row with one of three actions:
createupdateskip
Behavior depends on mapped match fields and their strategy:
- Match-only fields can skip unmatched rows
- Match-or-create fields can create unmatched rows
- Name-based matching can intentionally be "create only" to avoid unsafe assumptions
This makes matching policy explicit instead of buried in ad hoc conditions.
Execution: What Happens When Rows Fail?
The import runs as a queued job with retries and backoff, processing rows in chunks.
Key behaviors:
- Only unprocessed rows are handled
- Row-level processing marks success/failure without stopping the whole import
- Existing records are preloaded for update chunks
- Multi-choice field values merge on update
- Failed rows are captured with error messages and can be downloaded as CSV
One detail I like in this design: intra-import deduplication. If a row is initially marked create but a previous row in the same file already created that logical record, it can be promoted to update. That avoids duplicate records inside a single import run.
Operational Hardening in V3
Beyond the happy path, I added practical operations support:
- Transition lock to prevent double-starting the same import
- Import history view with created/updated/skipped/failed counts
- Signed failed-rows download
- Cleanup command for abandoned and terminal imports
The cleanup strategy is especially useful in production: completed/failed stores are removed after a short retention window, and stale abandoned imports are purged.
What This Says About Relaticle V3
The Import Wizard reflects broader V3 architecture principles:
- Workflow over one-shot scripts
- Staged processing over direct mutation
- Async jobs for expensive work
- Team-scoped safety as a default
- Extensibility via importer contracts and entity-link abstractions
Still a modular monolith, but with clearer boundaries and better operational behavior. That modularity-first approach is something I've written about more broadly in Building Scalable Systems: Practical Lessons.
If You're Building an Importer, My Practical Checklist
- Separate staging from final writes
- Make matching policy explicit (and user-visible)
- Support value-level corrections before commit
- Model row action as
create/update/skip - Keep a downloadable failed-row report
- Add cleanup from day one
- Test every stage (UI + jobs + validators + matchers)
Imports are one of those product surfaces where reliability compounds trust. If users get burned once by "mystery imports," they stop trusting the system.
For Relaticle V3, the goal was simple: make imports boring in production, even when the data isn't.
Building imports for your own product? I've made most of the mistakes already — happy to save you some. DM me on X or LinkedIn.